



关键词:计算社会科学,集体常识,人工智能
论文标题:量化个人和集体常识的框架
论文杂志:PNA
纸张地址:
常识的概念在各种环境中经常提到,例如每日对话,政治辩论和对人工智能的评估,因此人们可能会认为它的含义是毫无疑问的。然而,令人惊讶的是,尚未在经验上研究常识知识的固有属性(使声称具有共同的意义)以及在人群中共享多少(其“常见”)。 PNA中发表的最新文章通过在个人和集体层面引入正式量化常识的形式方法来解决这种令人困惑的情况。本文的作者之一是宾夕法尼亚大学社会学教授邓肯·瓦茨(Duncan J. Watts),也是小世界网络的提议者之一。

首先,研究人员通过人们倾向于就其主张和彼此的看法达成共识来定义个人主张和常识。其次,研究人员将常识的共同点形式化为一组人和主张之间的两部分图表,并通过查找集群(即比例p的人共享的主张的比例q来定义常识PQ。评估本文提出的框架,该数据集由2,04666名审阅者评估的4,407项索赔集,发现常识最接近有关每日物理现实的清晰明确的事实陈述。心理特性(例如社会感知)会影响一个人的常识,但令人惊讶的是,年龄或性别等人口统计学因素不会影响常识。最后,研究发现,集体常识很少见:最多只有少数人同意少量主张。这些结果共同削弱了普遍主义的普遍主义信念,并提出了有关其可变性的相关问题,这对人类和人工智能都具有重要意义。
本文的目的是为如何以超越个人偏见和不同观点的方式定义,衡量和理解常识的方式提供一个全新的观点,并在本文中为这一基本但难以捉摸的人类智力方面的广泛经验研究开辟了道路,通过提供一种解决常识固有的循环的方式。研究人员希望将来将此工具应用于大规模研究中,进一步促进了我们对常识及其在人类和人工智能中的作用的集体理解。
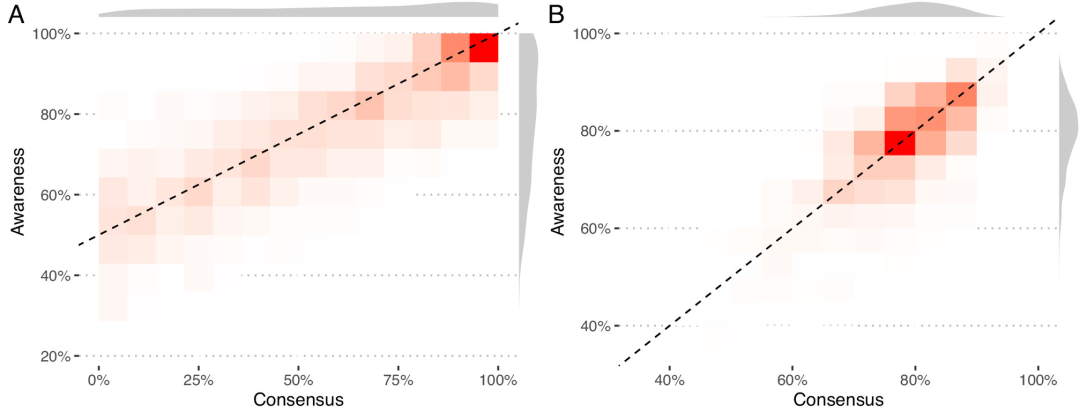
图1(a)一个密度图显示了所有主张的共识和认知情况,其中有边缘分布,其中对角线虚线表示共识和认知的校准程度。在低端,声称它实际上是基于人群之间的差异而基于随机判断。在高端,这是一个完全符合常识的说法。 (b)还显示了所有个体的共识和认知状况的密度图。
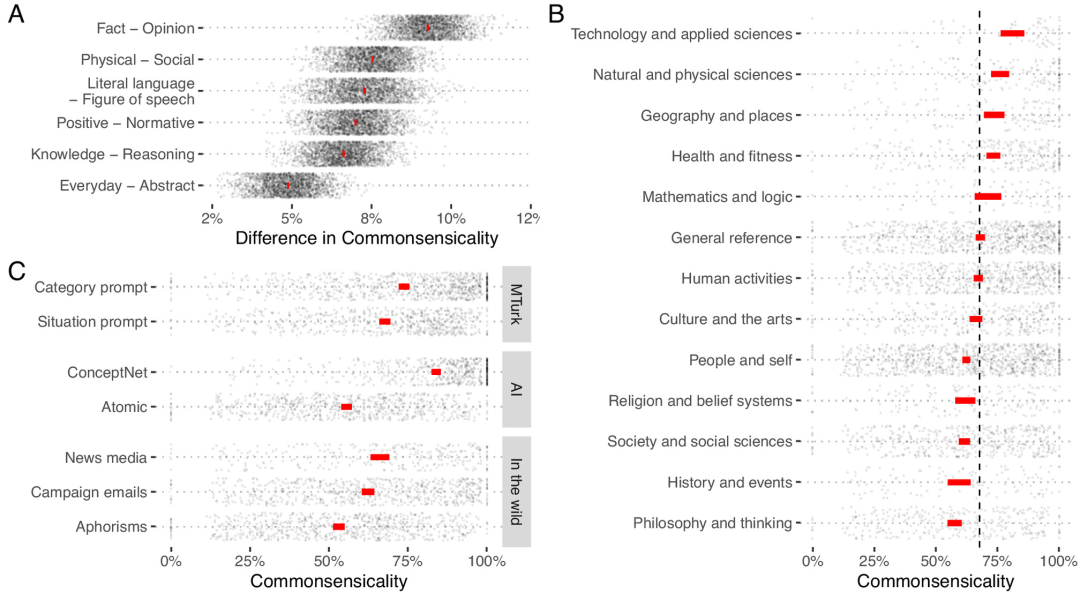
图2基于声称属性的常识,自助方法的平均服务方法为95%。 (a)具有和没有每个二元认识论属性的主张之间的常识平均差异。每个索赔都有每个属性的值,因此该面板中的每一行都均来自语料库中的所有主张。 (b)在每个知识类别中声称的常识,使用虚线表示跨类别的未加权平均值。每个主张都属于知识类别,因此该小组中的所有行都集体反映了语料库中的所有主张。 (c)来自每个来源的常见主张。与B相似,整个面板反映了语料库中的所有主张。
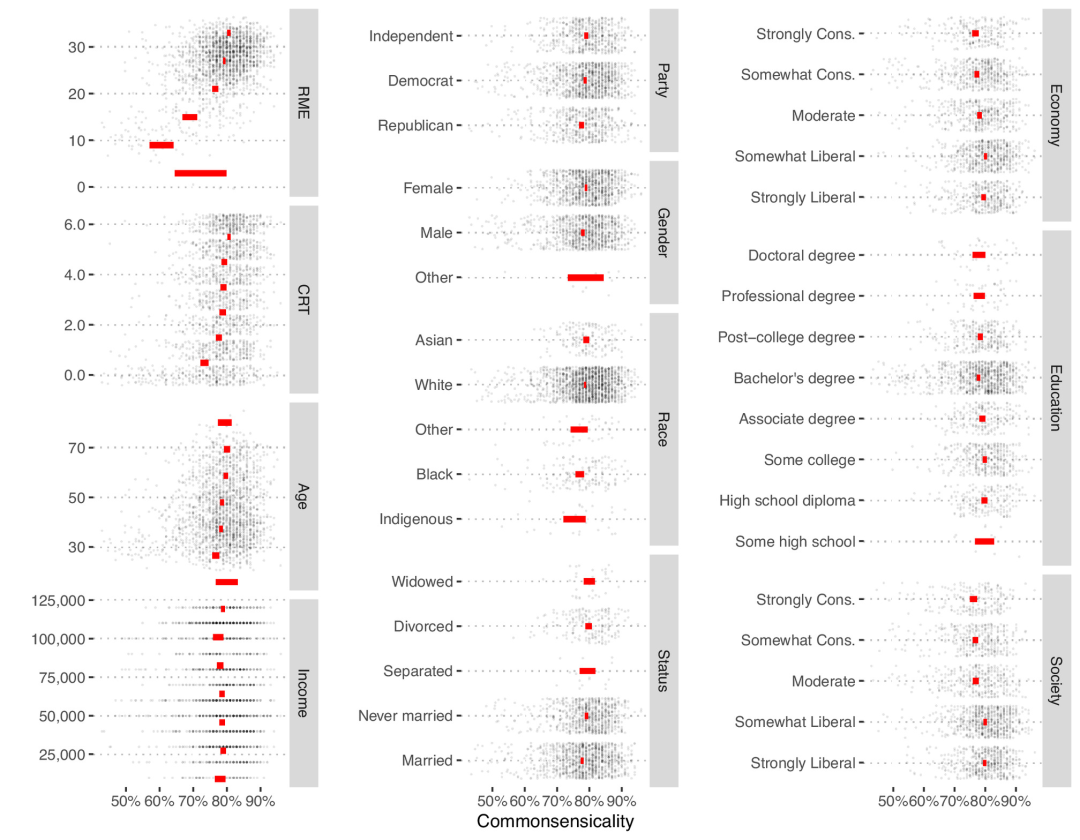
图3个人的常识。单个级别的人口统计属性是水平轴,垂直轴是常识。红色条形图显示了总体平均值的95%兼容间隔。收入为美元。左列显示组中的数值变量;中间列按值显示名义变量;右列显示顺序变量。
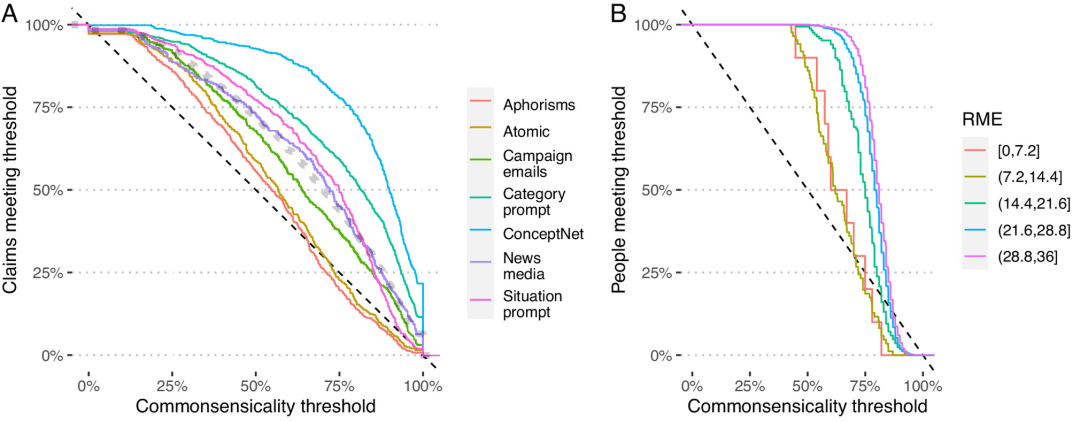
图4常识阈值。 (a)显示通过ECCDF图达到常识阈值的主张的比例,并根据索赔启动机制为其上色。灰点曲线表示整个语料库的分布。 (b)类似的ECCDF图显示了达到此阈值的人比例,将RME分数分为5桶。
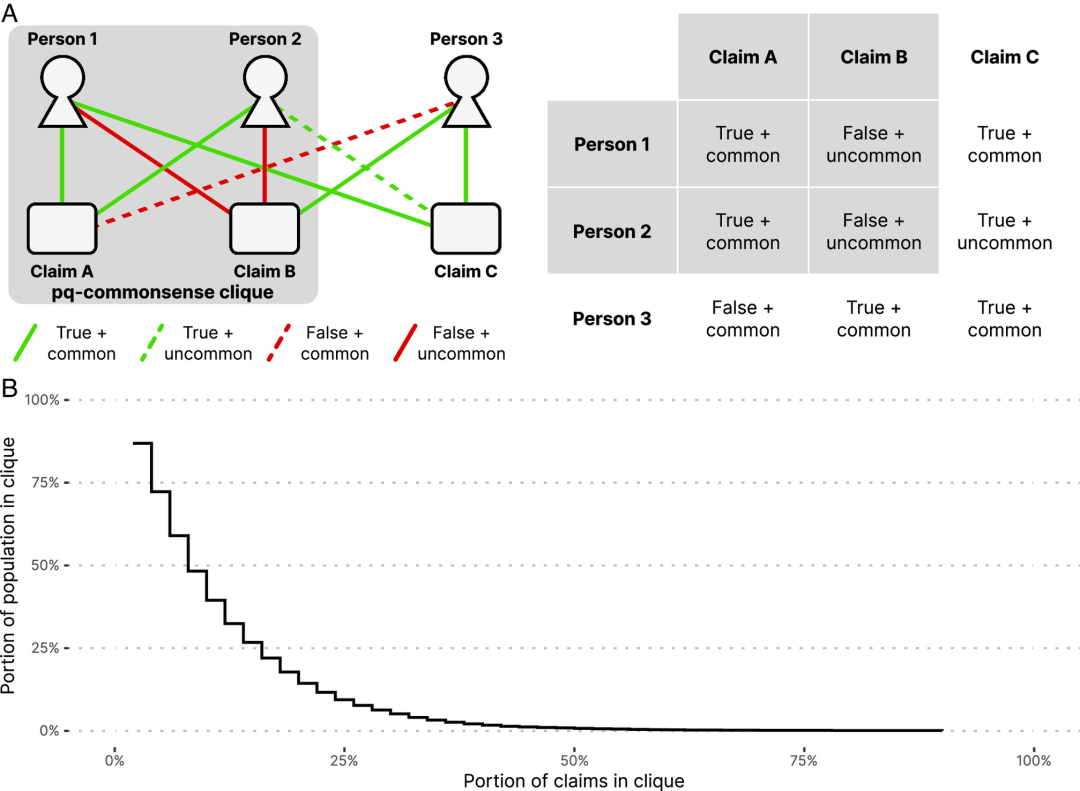
图5常识。 (a)一个包含3个人和3个主张的信念图,显示每个人的信念配置,矩阵显示了该图的形式表示,最大的集群标记为灰色。字符1和2具有相同的信念配置,其中包括声称A和B的相同信念。(b)在对整个人群的50项索赔进行示例调查之后,可以实现P,Q的最大常识价值PQ。信仰配置由多项式模型(F1 = 72.7%)预测,对未观察到的值。
汇编| Yu Mengjun
计算社会科学阅读俱乐部第2季
有关详细信息,请参阅:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请联系本站,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.izhongdian.com/html/tiyuwenda/9649.html





